There's little in this that independently affects brain power (that I know of), so there's nothing here that I'm marking with (Brain), but otherwise, in order, here are my body goals for 2014:
- Significantly greater range of motion for my right foot, less pain from both feet (Feet)
- Weight of less than 200 lbs. Waist of 32 inches or less. (Weight/Body Fat)
- Meeting daily steps goal of 6000 daily. Raising to AHA-standard 10,000 steps and meeting that. (Feet,Stamina/Endurance)
- At least one 5K race completed in 40 minutes or less. (Stamina/Endurance)
- A set of ten standard push-ups (Strength)
- One successful pull-up or chin-up (Strength)
Significantly greater range of motion for my right foot, less pain from both feet (Feet)
As previously mentioned, my feet are weird. My left foot shows -- showed? It's been a while since I saw the doctor -- signs of pronation and bunions, but my right foot is far far worse.
It is my belief that it has always been worse and I just never noticed until 42 years in. It might be the case that I can't fully fix the problem without surgery, and any invasive surgery is problematic and likely to leave it in a continually compromised state. I intend to use stretching and other non-invasive means to get it worked out.
Related, though, is the fact that the mere fact of hitting the American Heart Association's recommendation of 10,000 steps leads me to believe that my years of neglect as a mostly-sitting student and computer professional has caused muscle atrophy in my feet and ankles, and an amount of physical therapy that'll lead me through pain is necessary before I get to where they're where they should be.
I'm finding that, while my ankle hurts when I start moving, once I'm going for a while, the pain subsides. I'm thinking that I have to move more all the time to get my ankles to a better point.
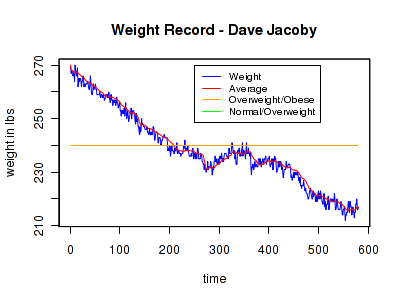
Weight of less than 200 lbs. Waist of 32 inches or less. (Weight/Body Fat)
I am on a downward trend, and the evidence tends to show that I have more to lose if I keep the way I am, but I'm into a time where many people hit a plateau due to the increased consumption around Christmas and the decreased activity due to Winter. I expect this, I hope to work against it, and I expect further loss come Spring. I suspect 2014's weight loss, unlike 2012 and 2013, will be something I have to work for.
I'm tossing in a Kickstarter-like stretch goal of getting and staying within 5 lbs of 180. I think much less than that and I'll look like a bean-pole, but we'll see.
Meeting daily steps goal of 6000 daily. Raising goal to AHA-standard 10,000 steps and meeting that. (Feet,Stamina/Endurance)
I dropped my daily steps goal in FitBit to 6000 steps because it seemed doable without heroic measures, and while I often have spike days above the goal -- even above the 10,000 step goal -- but weeks where my daily average is above 6000 are rare, and weeks when my worst days were above 6000 steps just do not exist.
Kinda goes with the first goal, and certainly relies on it. If my ankles and legs aren't happy, I won't be pushing myself to move.
At least one 5K race completed in 40 minutes or less. (Stamina/Endurance)
As mentioned before, I've "run" a 5K with a time of 45 minutes. I'm happy with it -- I came, I saw, I didn't stop, I got the t-shirt! -- but I believe I can do better. So, my goal here is to prove it.
A set of ten standard push-ups (Strength)
One successful pull-up or chin-up (Strength)
I am grouping these, as they are predicated on upper-body strength. There's a bunch of core in pushups, but that isn't my primary reason. I've been trying to keep body weight squats in my endurance work, like ten squats every lap, but I don't have a strong way to gauge that, nor a strong reason (pun intended) to work on it. (Did a 5K nature run followed by some Cross Fit including squats, and the squats made my thighs ache for the better part of a month. That is why I do squats.)
I also intend to get my form together for burpees (a perfectly sadistic exercise in it's own right, one where my form so far has been spastic and ill-disciplined), but that's that would be nice, not I will do this.
Up soon, at least before New Year, is my plans to achieve these. After that, progress reports as I knock these things down.












{kind=link}